- Runnable/Callable
- Runnable接口只有一个没有返回值的方法。
- Callable与之类似,除了它有一个返回值。
- 线程
- scala并发是建立在java并发模型基础上的。
- 一个线程需要一个Runnable。你必须用线程的start方法来运行Runnable。
- Executors
- 你可以通过Executors对象的静态方法得到一个ExecutorService对象。
- Futures
- Future代表异步计算。
- 你可以把你的计算包装在Future中,当你需要计算结果的时候,你只需要调用一个阻塞的get()方法就可以了。
- 一个FutureTask是一个Runnable实现,就是被设计为由Executor运行的。
- 线程安全问题
- 三种工具
- 同步:互斥锁(Mutex)提供所有权语义。
- volatile:synchronized云溪更细粒度的锁,而volatile则对每次访问同步。
- AtomicReference
- 这个成本是什么?synchronized往往是最好的选择。
- CountDownLatch
- AtomicInteger/Long
- AtomicBoolean
- ReadWriteLocks
Tuesday, May 20, 2014
scala课堂:Concurrence in Scala
scala课堂:More collections
- 基础知识
- 表 List
- 集 Set
- 序列 Seq
- 映射 Map
- 层次结构
- Traversable
- Iterable
- Seq 序列
- Set 集
- Map
- 常用的子类
- HashSet和HashMap的快速查找,这些集合的最常用的形式。
- TreeMap是SortedMap的一个子类,它能让你进行有序访问。
- Vector快速随机选择和快速更新。
- Range等间隔的Int有序序列。你经常会在for循环看到。
- Ranges支持标准的函数组合子。
- 一些描述性的特质
- IndexSeq快速随机访问元素和一个快速的长度操作。
- LinearSeq通过head快速访问第一个元素,也有一个快速的tail操作。
- 可变集合
- HashMap定义了getOrElseUpdate,+=
scala课堂:高级类型
- 视界(“类型类”)
- 一个视界指定一个类型可以被“看作是”另一个类型。这对对象的只读操作是很有用的。
- 隐函数允许类型自动转换。更确切的说,在隐式函数可以帮助满足类型推断时,它们允许按需的函数应用。
- 视界,就像类型边界,要求对给定的类型存在这样一个函数。你可以使用<%指定类型限制。
- 其他类型限制
- 方法可以通过隐含参数执行更复杂的类型限制。
- 使用视图进行泛型编程。
- 上下文边界和implicitly[]。
- 更高级多态性类型和特设多态性
- scala可以对“更高阶”的类型进行抽象。
- F-界多态性
- 结构类型
- 抽象类型成员
- 类型擦除和清单
这部分和上部分的很多内容还不理解,后续需查阅其他资料学习。
scala课堂:类型与多态基础
- 什么是静态类型?它们为什么有用?
- 类型允许你表示函数的定义域和值域。
- scala中的类型
- 参数化多态性
- 类型推断
- 存在量化
- 视窗
- 参数化多态性:
- 多态性是在不影响静态类型丰富性的前提下,用来编写通用代码的。
- scala有秩1多态性。
- 类型推断
- scala中所有类型推断是局部的
- 变性 Variance
- scala的类型系统必须同时解释类层次和多态性。类层次结构可以表达子类关系。
- 变性注解允许你表达类层次结构和多态类型之间的关系。
- 边界
- scala允许你通过边界来限制多态变量。
- 量化
scala课堂:模式匹配与函数组合
- 函数组合
- 让我们创建两个函数:f(x)和g(x)。
- compose:compose组合其他函数形成一个新的函数f(g(x))。
- andThen:andThen和compose很像,但是调用顺序是先调用第一个函数,然后调用第二个,即g(f(x))。
- 柯里化 vs 偏应用
- case语句是一个名为PartialFunction的函数的子类。
- 多个case语句的集合是共同组合在一起的多个PartialFunction。
- 理解PartialFunction(偏函数)
- 对给定的输入参数类型,偏函数只能接受该类型的某些特定的值。
- isDefinedAt是PartialFunction的一个方法,用来确定PartialFunction是否能接受一个给定的参数。
- 主要偏函数和我们前面提到的部分应用函数是无关的。
- case之谜!
Thursday, May 15, 2014
统计检定 Part1
- 目的
- 根据样本资讯,检定关于一个或多个群体参数值之假说。
- 统计检定之五大步骤
- 设立
- 虚无假说 Ho
- 对立假说 Ha
- 指定显著水准
- 决定适当之检定统计量
- 决定弃却域
- 下结论
- 假说
- 关于一个或多个群体参数值的一段叙述。
- 对立假说 Alternative Hypothesis
- 虚无假说 Null Hypothesis
- 虚无假说为对立假说的相反
- 注意:
- 永远先设立Ha
- “=”只能放在Ho
- 如何设立假说
- 假说检定之种类
- 单边检定
- 双边检定
- 两种可能的误差
- 型一误差:当Ho是对的,检定结果却判断其为错的,而推翻Ho。
- 型二误差:当Ho是错的,检定结果却判断其为对的,而不推翻Ho。
- 显著水准 (Level of Significance)
scala课堂 集合
- 基本数据结构
- 列表 List
- 集 Set:集没有重复。
- 元组 Tuple
- 元组是在不使用类的前提下,将元素组合起来形成简单的逻辑集合。
- 使用位置下标来读取对象,而且这个下标基于1。
- 元组可以很好的与模式匹配相结合。
- 在创建两个元素的元组时,可以使用特殊语法:->
- 映射 Map
- 它可以持有基本数据类型。
- 映射的值可以是映射甚至是函数。
- 选项Option
- Option是一个表示有可能包含值的容器。
- Option本身是泛型的,并且有两个子类:Some[T]或None。
- 我们建议使用getOrElse或模式匹配处理这个结果,getOrElse让你轻松定义一个默认值。
- 函数子(Functional Combinators)
- map:对列表中的每个元素应用一个函数,返回应用后的元素所组成的列表。
- foreach:
- 很像map,但没有返回值。
- foreach仅用于有副作用(side-effects)的函数。
- filter:移除任何对传入函数计算结果为false的元素。
- zip:将两个列表的内容聚合到一个对偶列表中。
- partition:将使用给定的的谓词函数分割列表。
- find:返回集合中的一个匹配谓词函数的元素。
- drop & dropWhile:
- drop将删除前i个元素。
- dropWhile将删除元素直到找到的一个匹配谓词函数的元素。
- foldLeft:0为初始值,m作为一个累加器。
- foldRight:和foldLeft一样,只是运行过程相反。
- flatten:将嵌套结构扁平化为一个层次的集合。
- flatMap:
- 是一种常用的组合子,结合映射[mapping]和扁平化[flattening]。
- flatMap需要一个处理嵌套列表的函数,然后将结果串联起来。
- 可以把它看做是“先映射后扁平化”的快捷操作。
- 扩展函数组合子:上面所展示的每一个函数组合子都可以用fold方法实现。
- Map?
- 所有展示的函数组合子都可以在Map上使用。
- Map可以被看作是一个二元组的列表,所以你写的函数要处理一个键和值的二元组。
Tuesday, May 13, 2014
scala课堂 基础知识(续)
- 单例对象
- 单例对象用于持有一个类的唯一实例,通常用于工厂模式。
- 单例对象可以和类具有相同的名称,此时该对象也被称为“伴生对象”。我们通常将伴生对象作为工厂使用。
- 函数即对象
- 函数是一些特质的集合。
- 可以使用更直观快捷的extends (Int => Int)代替extends Function1[Int, Int]
- 包
- 值和函数不能在类或单例对象之外定义。单例对象是组织静态函数(static function)的有效工具。
- 模式匹配:scala中最有用的部分之一
- 匹配值/使用守卫进行匹配
- 匹配类型:你可以使用match来分别处理不同类型的值
- 匹配类成员
- 样本类 Case Classes:使用样本类可以方便的存储和匹配类的内容。你不用new就可以创建它们。
- 异常:Scala中的异常可以在try-catch-finally语法中通过模式匹配使用。
- Other
- trait Function1[-T1, +R] extends AnyRef : A function of 1 parameter, Self Type : (T1) => R
常态分布
- 常态几率分布:
- 自然界所观察到的许多连续型随机变数常呈钟形分布,又称为常态分布(Normal Distribution)。
- 常态分布的几率分布函数:
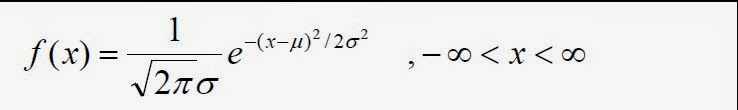
- 参数:pie,e,群体平均数,群体变异数。
- 常态几率分布的特性。
- 群体平均数(位置参数 Location parameter)和群体变异数(分散参数 Dispersion parameter)对常态曲线的影响。
- 标准常态分布几率表:
- 平均数为0,标准差为1之常态分布称为标准常态分布(Standard Normal Distribution)。
- 常态曲线之下面积代表几率。
- 检查数据是否呈常态分布:
- 利用直方图
- 利用常态几率图
- 利用统计检定
Monday, May 12, 2014
scala课堂 基础
- 匿名函数
- 你可以传递匿名函数,或将其保存成不变量。
- 部分应用
- Scala使用下划线表示不同上下文中的不同事物,你通常可以把它看作是一个没有命名的神奇通配符。
- 柯里化函数
- 你可以对任何多参数函数执行柯里化。
(adder _).curried
- 可变长度参数
def capitalizeAll(args: String*) = { args.map { arg => arg.capitalize } }- 特质(Traits):特质是一些字段和行为的合集,可以扩展和混入(mixin)你的类中;通过with关键字,一个类可以扩展多个特质。
- 什么时候应该是用特质而不是抽象类:
- 优先使用特质
- 如果你需要构造函数参数,使用抽象类
- 类型:其实函数也可以是泛型的,来适用于所有类型。
Scala Reading Notes ch3-ch4
- First Steps in Scala
- One of the main characteristics of a functional language is that functions are first class construct, and that's very true in Scala.
- Iterate with foreach and for : args.foreach(arg => println(arg)).
- In this code, you call the foreach method on args, and pass in a function.
- args.foreach((arg : String) => println(arg))
- args.foreach(println)
- for (arg <- arg="" args="" li="" println="">
- Next Steps in Scala
- val greetStrings = new Array[String](3)
- greetStrings(0) = "Hello" ...
- for (i <- 0="" 2="" greetstrings="" i="" li="" print="" to="">
- val greetStrings : Array[String] = new Array[String](3)
- greetString(0) = "Hello" will be transformed into greetStrings.update(0, "Hello")
- val numNames = Array("zero", "one", "two")
- val oneTwo = List(1, 2); val threeFour = List(3, 4); val oneTwoThreeFour = oneTwo ::: ThreeFour;
- val pair = (99, "Luftballons"); println(pair._1); println(pair._2)
- var jetSet = Set("Boeing", "Airbus"); jetSet += "Lear"; jetSet.contains"Cessna";
- val hashSet = HashSet("Tomatoes", "Chilies")
- val treasureMap = Map[Int, String](); treasureMap += (1 -> "Go to island.");
- Something
- (x: Int, y:Int) => x + y : 这是一个匿名函数的定义,可以把它赋值给一个不变量;
- def add(x: Int, y: Int): Int = {x + y} : 这是一个正常函数的定义;
- Remeber : Concise is Nice !
- thrill.mkString(", ") equals ",".join(thrill) in python
Thursday, May 8, 2014
statistics指标
集中趋势指标
- 中位数:代表中心
- 最中间的数值
- 群体中位数:小写希腊字 eta
- 样本中位数:小写罗马字 x tilde
- 找中位数之方法:资料重新排序
- n=奇数:(n+1)/2
- n=偶数:n/2和n/2+1的平均数
- 众数(MODE):出现次数最多
- 众数不是唯一的
- 平均、中位数唯一
- 使用场景:
- 平均数对离群值非常敏感,中位数和众数不敏感,因此不使用平均数
- 同时考量平均数和中位数
分散趋势指标
- 分散趋势
- 全距(range)
- R=最大值-最小值
- 出现离群值或样本数很大时,不能很好的衡量
- 相同之全距,不同之分布
- 变异数:离中趋势
- 群体变异数
- 样本变异数:(平方和-和平方/n)/n-1
- 标准差:分散程度
- 群体标准差
- 样本标准差
- 偏态:数据分布的形态
- 对称:平均数=中位数=众数
- 右偏,正偏:众数<中位数<平均数
- 左偏,负偏:平均数<中位数<众数
- 偏态系数
- 样本偏态系数,3次方(无单位量数)
- =0 对称
- >0 右偏
- <0 li="">
- 峰度系数
- 4次方(无单位量数)
- =0 常态
- >0 高峡
- <0 li="">
数据特征值之应用
- 经验法则:常态分布下,68-95-99.73法则
- 盒须图(box-whisker plot):min,q1,md,q3,max
- 展示资料特征
- 同时比较数组资料
- 集中趋势,离中趋势,形态
- 离群值
hive命令
hive命令:
1、创建表:
create external table beifen_rld (userid BIGINT)
partitioned by (data_date STRING)
row format delimited
fields terminated by '\t'
stored as textfile;
hive> create external table user_click_stat (userid BIGINT, winfoid BIGINT, charge double, click BIGINT, wordid BIGINT)
> partitioned by (data_date STRING)
> row format delimited
> fields terminated by '\t'
> stored as textfile;
2、增加partition:
alter table beifen_pld add partition (data_date=20140318)
location '/beifen_pld/20140318';
hive> alter table user_click_stat add partition (data_date = 20140505)
> location '/user_click_data/20140505';
3、查询并插入:
from
( from beifen_pld select * where data_date='$date') tmp
insert overwrite table beifen_rld partition(data_date='$date')
select userid;
hive> from
> ( from user_click_stat select userid, count(winfoid) as winfoid_num, sum(charge) as charge, sum(click) as click
> where data_date='20140505' group by userid) tmp
> insert overwrite table user_click_sum partition(data_date = '20140505')
> select *;
1、创建表:
create external table beifen_rld (userid BIGINT)
partitioned by (data_date STRING)
row format delimited
fields terminated by '\t'
stored as textfile;
hive> create external table user_click_stat (userid BIGINT, winfoid BIGINT, charge double, click BIGINT, wordid BIGINT)
> partitioned by (data_date STRING)
> row format delimited
> fields terminated by '\t'
> stored as textfile;
2、增加partition:
alter table beifen_pld add partition (data_date=20140318)
location '/beifen_pld/20140318';
hive> alter table user_click_stat add partition (data_date = 20140505)
> location '/user_click_data/20140505';
3、查询并插入:
from
( from beifen_pld select * where data_date='$date') tmp
insert overwrite table beifen_rld partition(data_date='$date')
select userid;
hive> from
> ( from user_click_stat select userid, count(winfoid) as winfoid_num, sum(charge) as charge, sum(click) as click
> where data_date='20140505' group by userid) tmp
> insert overwrite table user_click_sum partition(data_date = '20140505')
> select *;
Subscribe to:
Posts (Atom)